1 - An Introduction to Large Language Models
What Is Language AI?
Language AI is a subfield of AI that focuses on developing technologies capable of understanding, processing, and generating human language.
A Recent History of Language AI
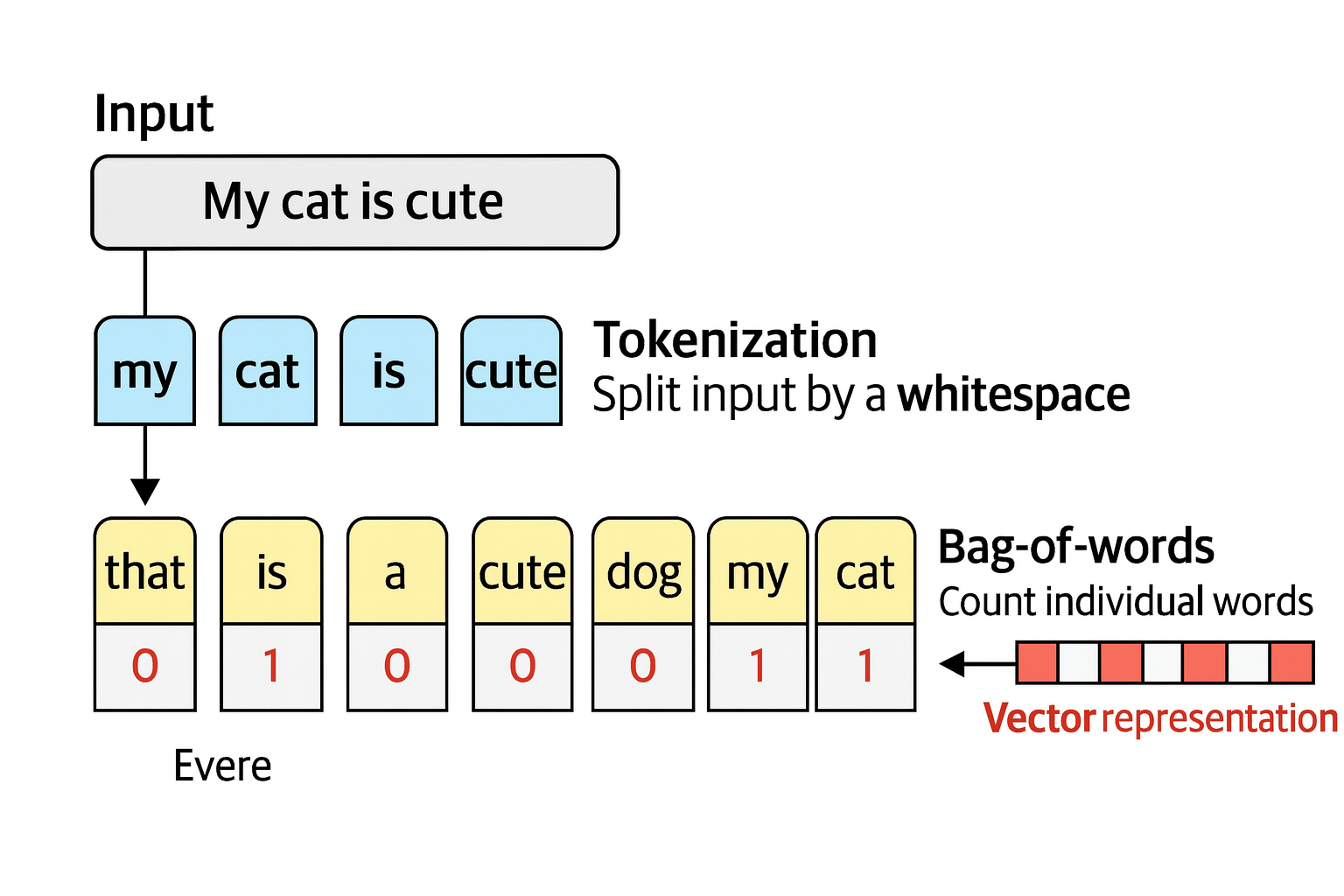
Representing Language as a Bag-of-Words
Steps:
- Tokenization: split up the sentence into individual words or subwords (tokens)
- Create a vocabulary: combine all unique words from each sentence to create the vocabulary that can be used to represent the sentences
- Create a bag-of-words by counting how often a word in each sentence appears
That is, a bag-of-words model create representations of text in the form of numbers (or vectors), but it ignores the semantic nature or the meaning of the text by considering language as a bag of words.
Better Representations with Dense Vector Embeddings
word2vec (released in 2013) attempts to capture the meaning of text in embeddings.
Steps:
- Use neural network with interconnected layers of nodes to process info.
- Assign each word a vector embedding with initialized random values.
- Take pairs of words from the training data, and train model to predict whether they are likely to be neighbors in a sentence.
- word2vec learns the relationship between words and distills the info into the embedding.
- Now if two words tend to have the same neighbors, their embeddings will be closer.
Embeddings attempt to capture meaning by representing the properties of words, for example, “baby” may score high on the properties “newborn” and “human”, and score low in properties “fruit”. In practice, the properties are often obscure and seldom relate to a single humanly identifiable concept, but makes sense to translate human language to compute language.
Types of Embeddings
Different levels of embeddings indicate different levels of abstractions (word vs sentence).
- word embeddings (e.g., word2vec)
- sentence embeddings
- document embeddings (e.g., bag-of-words)
Encoding and Decoding Context with Attention
How to switch to the dynamic embeddings so the meaning of words is dependent on its context? For example, “bank” can refer a financial bank, or the bank of a river.
Method 1: Recurrent neural networks (RNNs) - it models the word sequences as an additional input. It encodes to represent an input sentence, and decodes to generate an output sentence. However, it is difficult to deal with longer sentences with one single embedding to represent the entire input.
Method 2: Attention feature - To solve the long sentence embedding issue of RNN, attention is added to the decoder step. It selectively determines which words are most important in a given sentence, and allows a model to focus on parts of the input sequence that are relevant. That is, the input of the generation/decoding step is now the (1). context embedding generated by encoder (2). the hidden states of all input words as signal for each input word related to the potential output.
Drawback: Method 1 + 2 has a sequential nature and prevents parallelization during the training of the model.
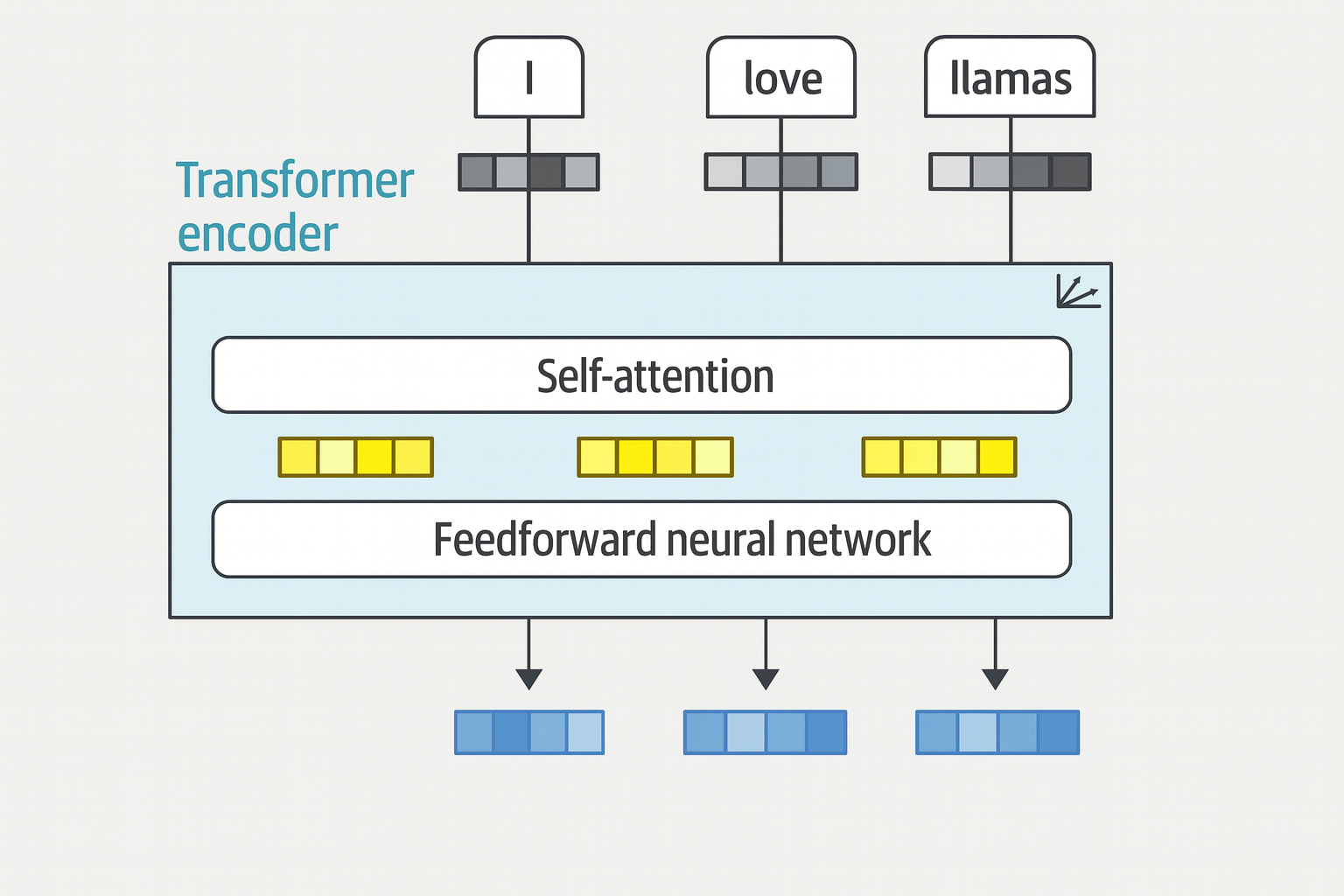
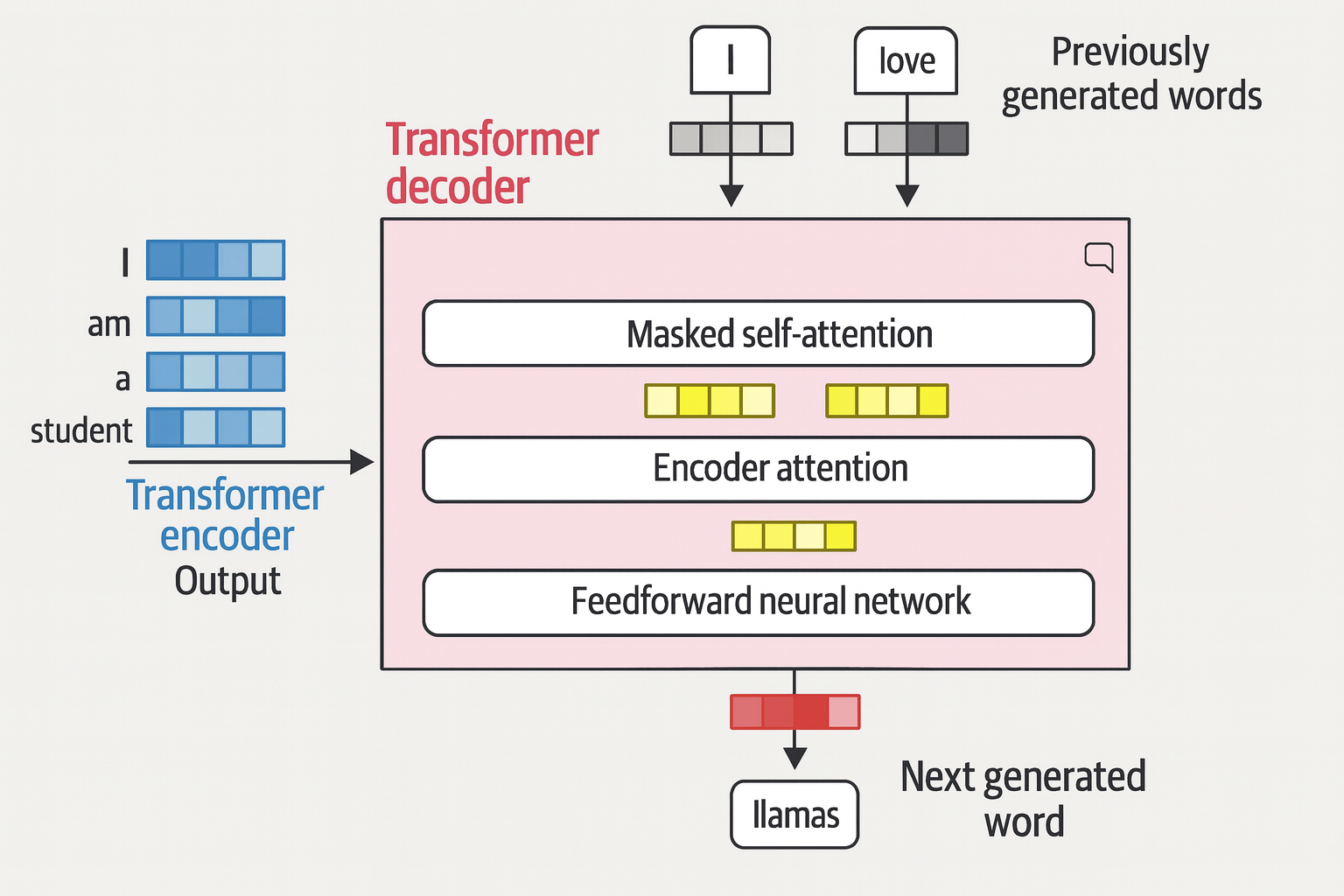
Attention Is All You Need
A network architecture called Transformer is
- solely based on the attention mechanism
- removed the recurrent network, which makes it ideal for parallel training
- remains autoregressive - consume each generated word before creating a new word
Two blocks in the transformer architecture: encoder and decoder
- Common layers: self-attention and feedforward neural network
- Unique layer of decoder: a layer to pay attention to the output of the encoder
Representation Models: Encoder-Only Models
Bidirectional Encoder Representations (BERT) is an encoder-only architecture that focuses on representing language, and the encoder stacks are training with masked language modeling - masks part of the input for the model to predict, to allow BERT to create better representations of the input.
Use case:
- Transfer learning: First pretrain (e.g., on entire wikipedia) and then fine-tune it for a specific task (e.g., classification, named entity recognition, clustering, semantic search, etc.)
- Feature extraction machine: BERT-like models generate embeddings at almost every step in their architecture, thus making extracting features possible without the fine-tuning for a specific task.
Generative Models: Decoder-Only Models
Focus on generating text like GPT.
The Training Paradigm of Large Language Models
For tradition machine learning tasks, it usually involves training a model for a specific task (e.g., classification) with one-step process. In contrast, creating LLMs usually consists of two steps:
- Language modeling (pretraining): Train on a vast corpus of internet text allowing model to learn grammer, context, and language patterns. The output model is a foundational model or base model.
- Fine-tuning (post-training): Further train the previous model on a narrower task.
Large Language Model Applications: What Makes Them So Useful?
Common tasks and techniques:
- Detecting review sentiment (supervised learning)
- Developing system to find common topics in ticket issues (unsupervised learning)
- Building a system for retrieval and inspection of relevant documents (e.g., RAG)
- Constructing chatbot with external resources
- Constructing LLM of writing recipes based on fridge food picture (multi-modality)
- Many more…