11 - Fine-Tuning Representation Models for Classification
Supervised Classification
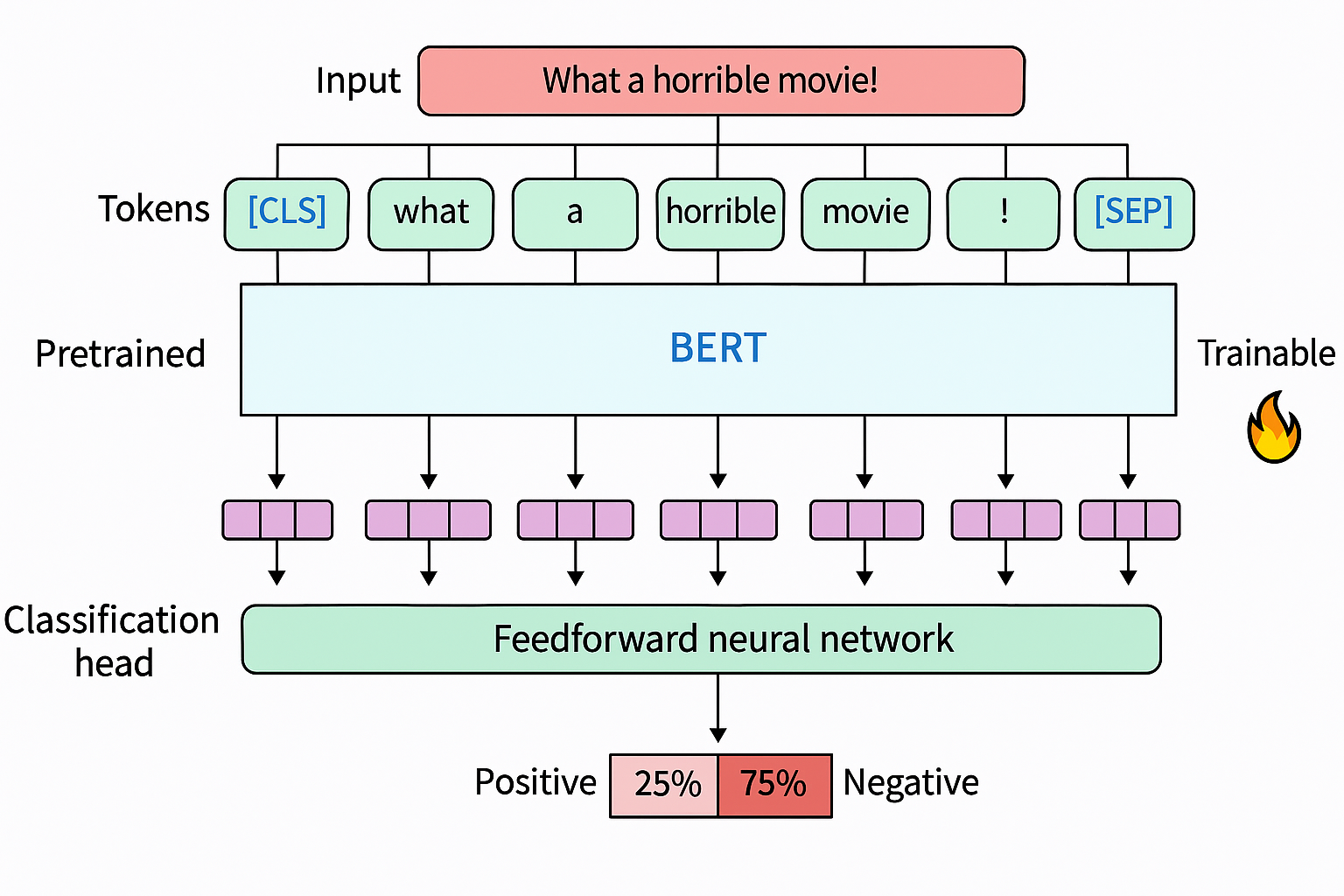
In this section, we take a supervised approach to allow both the model and the classification head to be udpated during traning . For example, for a task-specific model, we can fine-tune both the representation model and the classification head as a single architecture as shown below.
Few-Shot Classification
Few-show classification is a technique within supervised classification to have a classifier learn target labels based on only a few labeled examples. It is great when we need to you a classification task but do not have many labeled data points.
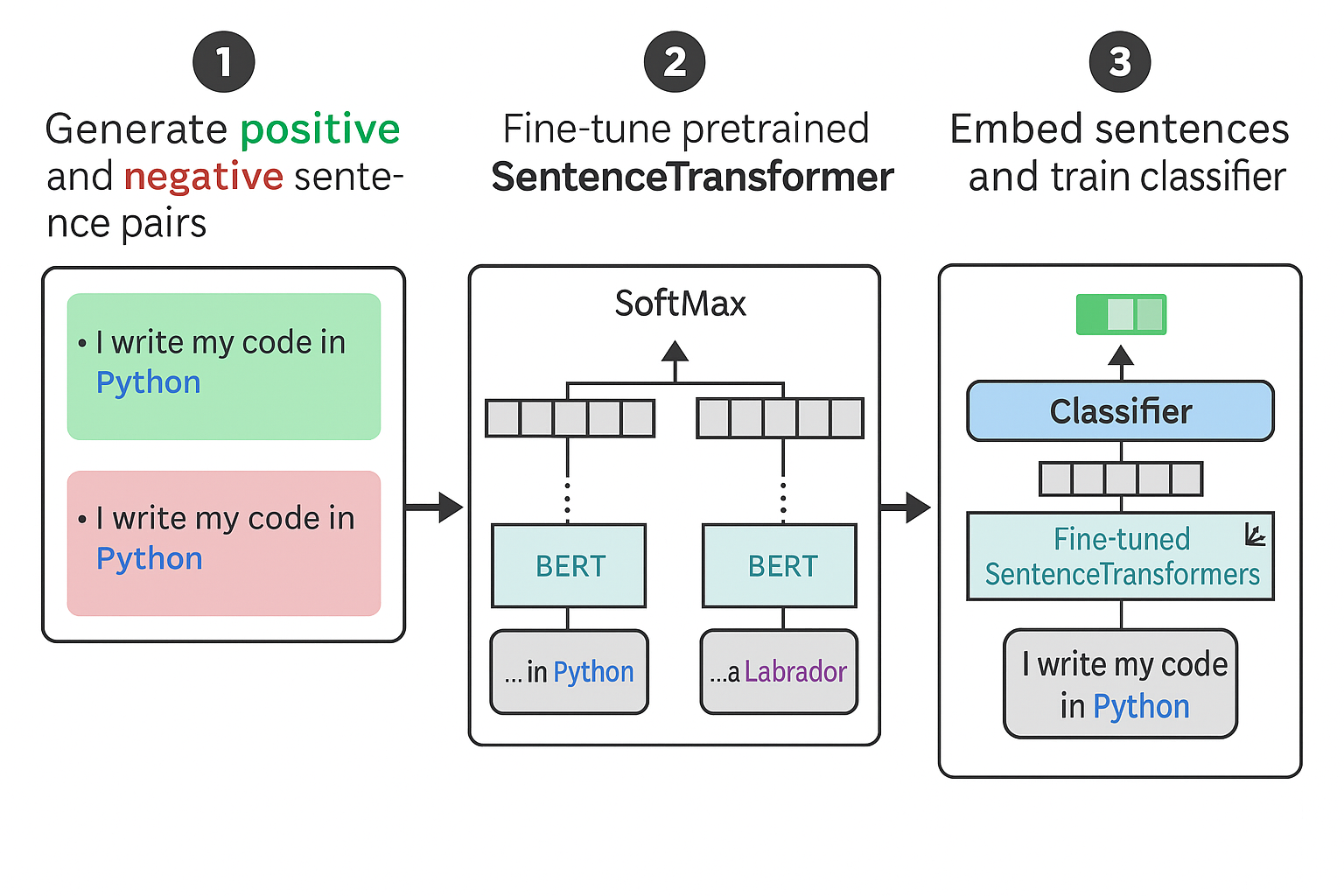
An exmple efficient framework of the few-shot text classifiction is SetFit has the following 3 steps:
- Sampling training data based on in-class and out-class selection of labeled data
- Fine-tuning a pretrained embedding model based on the above training data. The goal is to create embeddings that are tuned to the classification task
- Train a classifier by creating a classification head on top of the embedding model and train it using the above training data
Continued Pretraining with Masked Language Modeling
Instead of adopting the two-step approach (e.g., pretain, then fine-tune) above, continued pretaining with masked language modeling add another step between them to continue training the model with data from our domain.
Named-Entity Recognition
Name-entity recoginition (NER) is helpful for de-identification and anonymization tasks when there is sensitive data. It allows for the classification of individual tokens and/or words, including people and locations.