9 - Multimodal Large Language Models
We explore how images are converted to numerical representations via an adaption of the original transformer technique, and show how LLMs can be extended to include vision tasks.
Transformers for Vision
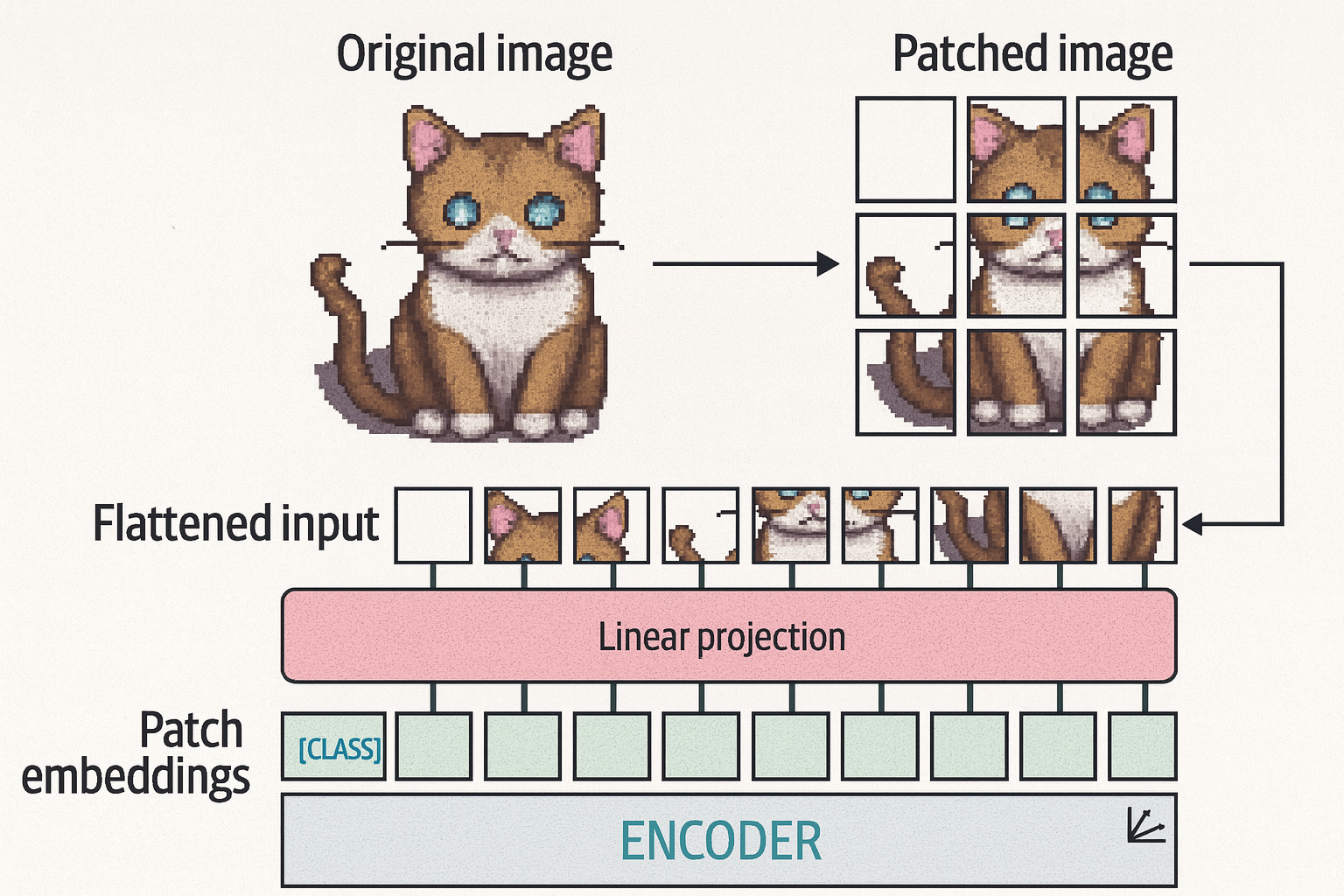
Vision Transformer (ViT) is used to transform the unstructured data such as an image into representations that can be used for various tasks (e.g., classification on if an image has a cat in it). It works as follows:
- Convert an image into patches of images (e.g., convert a 512 by 512 pixels image into 16 by 16 patches)
- Linearly embed the patches to create numerical representations (i.e., embeddings) that can be used as the input of the transformer model
Multimodal Embedding Models
Contrastive language-image pre-training (CLIP) is a multimodal embedding model that connects text and images. It first encode both the image and text (the caption of the image) with imasge and text encoders, respectively, then train to optimize for similarity between the embeddings (i.e., maximize similarity for similar image/caption pairs and minimize for dissimilar pairs).