6 - Prompt Engineering
WE will explore generative models, prompt engineering, reasoning with generative models, verification, and evaluation of the outputs.
Using Text Generation Models
The output of the generation models can be controlled via:
- prompt engieering (see more in the next subsection)
- model parameters adjustment
temperature: teh randomness or creativity of the text generatedtop_p: nucleus sampling - a technique that controls which subset of tokens (nucleus) the LLM can consider
Intro to Prompt Engineering (PE)
The goal of PE is to elicit a useful and desired response from the model by carefully designing the input (prompts) of the LLM.
Some common prompting techniques used to improve the quality of the output:
- Specificity: Accurately describe what you want to achive (e.g., “write a descriptiont for a product in less than two sentences and use a formal tone” is more specific than “write a description for a product”)
- Hallucination: To avoid generated incorrect info, we can ask LLM to generate answer ONLY when it knows it.
- Order: With longer prompts, info in the middle is often forgotten. So we should either begin or end the prompt with the instruction.
Advanced Prompt Engineering
- In order to describe what the LLM should do, accurate and specific descriptions can help LLM to understand the use case. For example, there are more advanced components of the prompts can be described in the figure below:
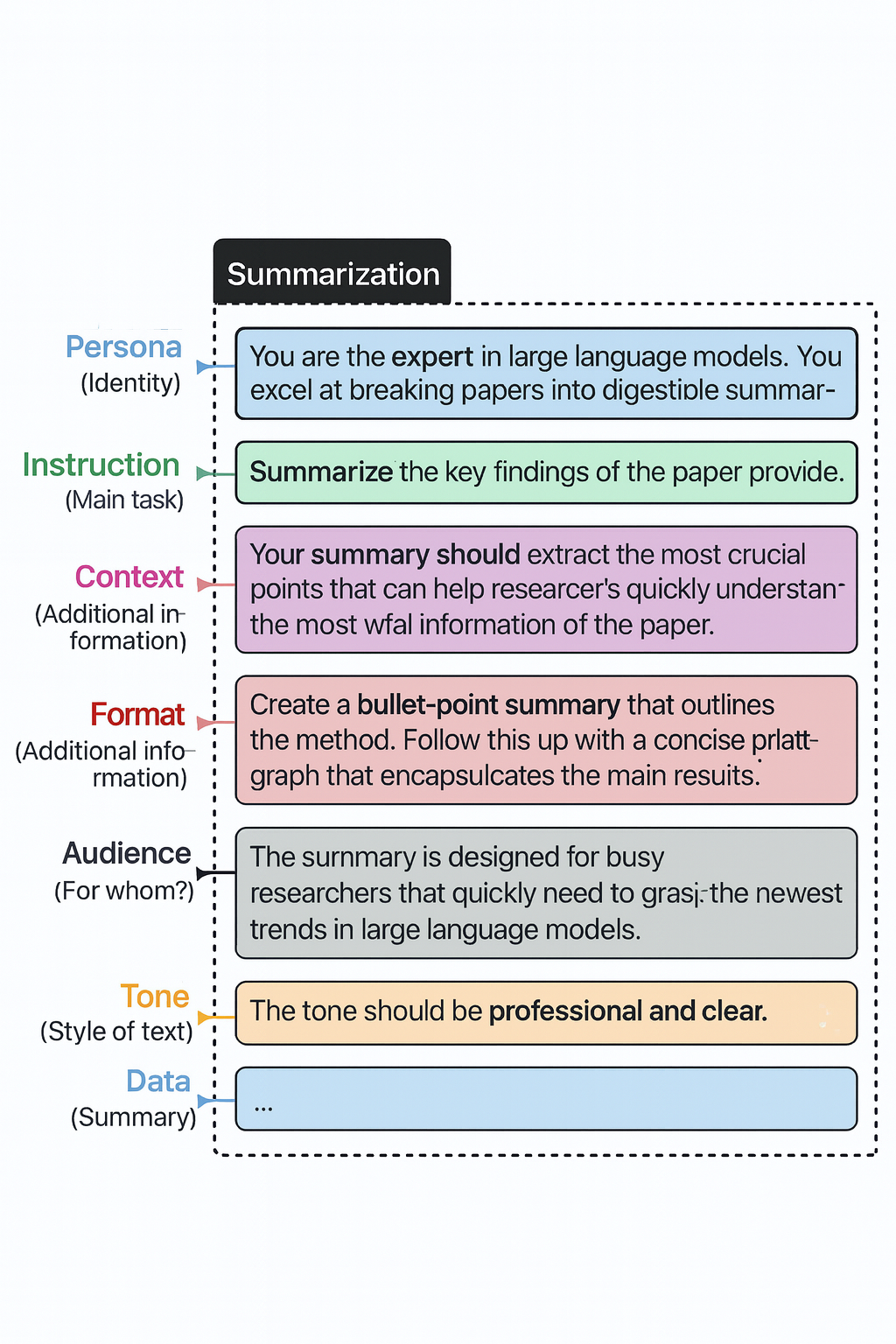
We can also provide the LLM with examples of exactly the thing that we want to achieve, that is, in-context learning
For highly complex use cases, instead of breaking the problem within one prompt, we can use multiple prompts: take the output of one prompt and use it as input for the next, thereby creating a continuous chain of interactions taht solves the problem.
Reasoning with Generative Models
Reasoning behavior of LLM models are generatelly considered to be demonstrated via memorization of training data and pattern matching.
Chain-of-Thought: Think Before Answering
Chain-of-thought is the first and major step toward complex reasoning in generative models, and it aims to have the generative model “think” first than answering the question directly without any reasoning. We could do either zero-shot reasoning (e.g., simply ask the model to provide reasoning such as saying “let’s think step-by-step”), or use one or more concrete examples when access available.
Self-Consistency: Sampling Outputs
Self-consistency samples the output by asking the generative model a same prompt multiple times and takes the majority result as the final result. Though it can improve performance accuracy, it becomes n times slower with n is the number of output samples.
Tree-of-Thought: Exploring Intermediate Steps
Different than the above methods which just scratch the surface of what is currently being done to mimic complex reasoning, tree-of-thought allows for an in-depth exploration: it breaks the complext reasoning steps into pieces, at each step, the generative model is prompted to explore different solutions to the problem, and then vote for the best solution and continue to next steps.
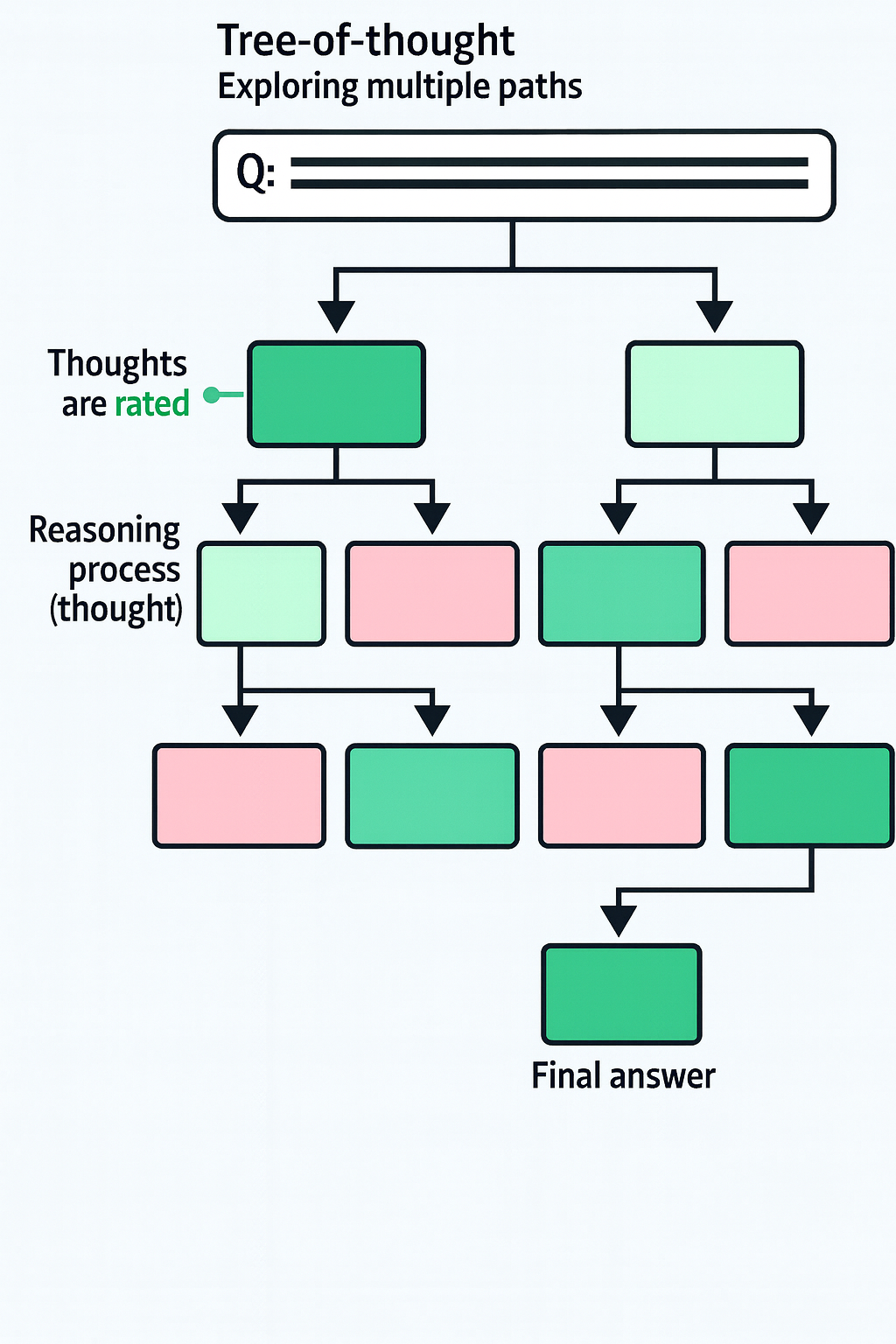
This method is helpful with multiple paths considered, but also requires many calls of the generative modles. A quicker way is to ask the model to mimic this behavior by emulating a conversation between multiple experts. They will question each other until they reach consensus.
Output Verification
It’s important that we verify the output of the model in production for a robust genAI application:
- is the output structured?
- is the output valid?
- is the output guardrailed with ethics or safety considerations?
- is the output accurate, coherent, or free from hallucination?