8 - Semantic Search and Retrieval-Augmented Generation (RAG)
Overview of Semantic Search and RAG
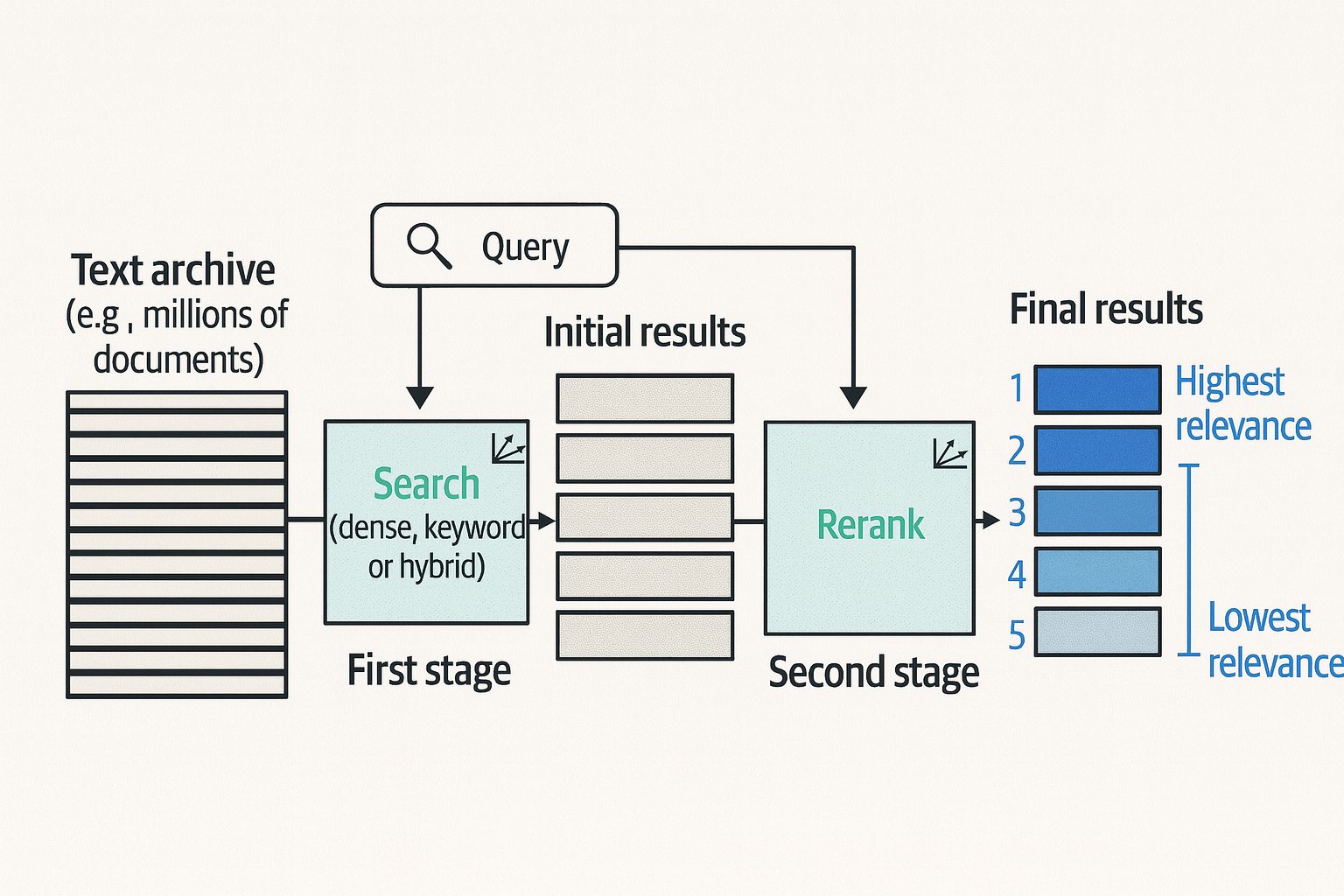
Semantic search enables searching by meaning, and not simply keyword. Three broad categories of models that can help us to better use language models for search (including semantic search) are:
Dense retrieval: Turn the search problem into retrieving the nearest neighbors of the search query by converting both the query and candidate documents into embeddings.
Reranking: Score the relevance of a subset of results against the query, and change the results order based on the scores
RAG: Text generation systems that incorporate search capabilities to reduce hallucinations, increase factuality, and/or gropund the generation model on a specific dataset.
Semantic Search with Language Models
Dense Retrieval
Dense retrieval relies on the property that search queries will be close to their relavant results in the embeddings space. Typical steps with dense retrieval:
- Embed the query by projecting it into the same space as our text achive
- Find the nearest documents to the query in that space as the returned search results
Note that we should build a search index for the text achive that we want to make searchable, so they can be retrieved later.
Caveats of dense retrieval
| Caveat | Solution |
|---|---|
| What happens if the texts don’t contain the answer? | - Set a threshold level (i.e., max distance for relevance) - Track whether users clicked a result (for feedback) |
| What if a user wants an exact match for a specific phrase? | Use hybrid search (combine semantic search with keyword search) instead of relying only on dense retrieval |
| What if the query is outside the domains the models were trained on? | Improve and expand the text archive; consider domain-specific data or models |
| What if a query asks for info that appears across many sentences? | Tune the chunking strategy (see “Ways to chunk long text” below) |
Table: Summary of dense retrieval caveats
Ways to chunk long text
Language models are usually limited in context sizes and we cannot feed very long texts. Also, longer texts may make it harder to find a small piece of info. As a result, we need to chunk the long texts into smaller pieces. There are several ways:
- Use a single vector to represent the whole document - it can satisfy some info needs, but not others. For example, it’s hard to search for a specific piece of info contained in an article in this method.
- Multiple vectors per document - It has full coverage of the text and tends to capture individual concepts better with more expressive search index, but more expensive.
The best way to chunk the long text depends on teh types of texts and queries the system anticipates.
Nearest neighbor search vs vector database
| Search method | Use case |
|---|---|
| Nearest neighbor | The number of vectors is small (e.g., thousands or tens of thousands of vectors) |
| Approximate nearest neighbor | Millions of vectors (example libraries: Annoy, FAISS) |
| Vector databases | Millions or more vectors (example DB: Pinecone). Allows adding or deleting vectors without rebuilding the index, and provides filtering and other customization beyond simple vector distances. |
Table: Summary of search method and use cases.
Fine-tuning text embedding models for dense retrieval
Retrieval needs to be optimized in text embeddings instead of just token embeddings to improve the performance of an LLM. This can be done by fine-tuning the LLM models with training data of queries and relavant results.
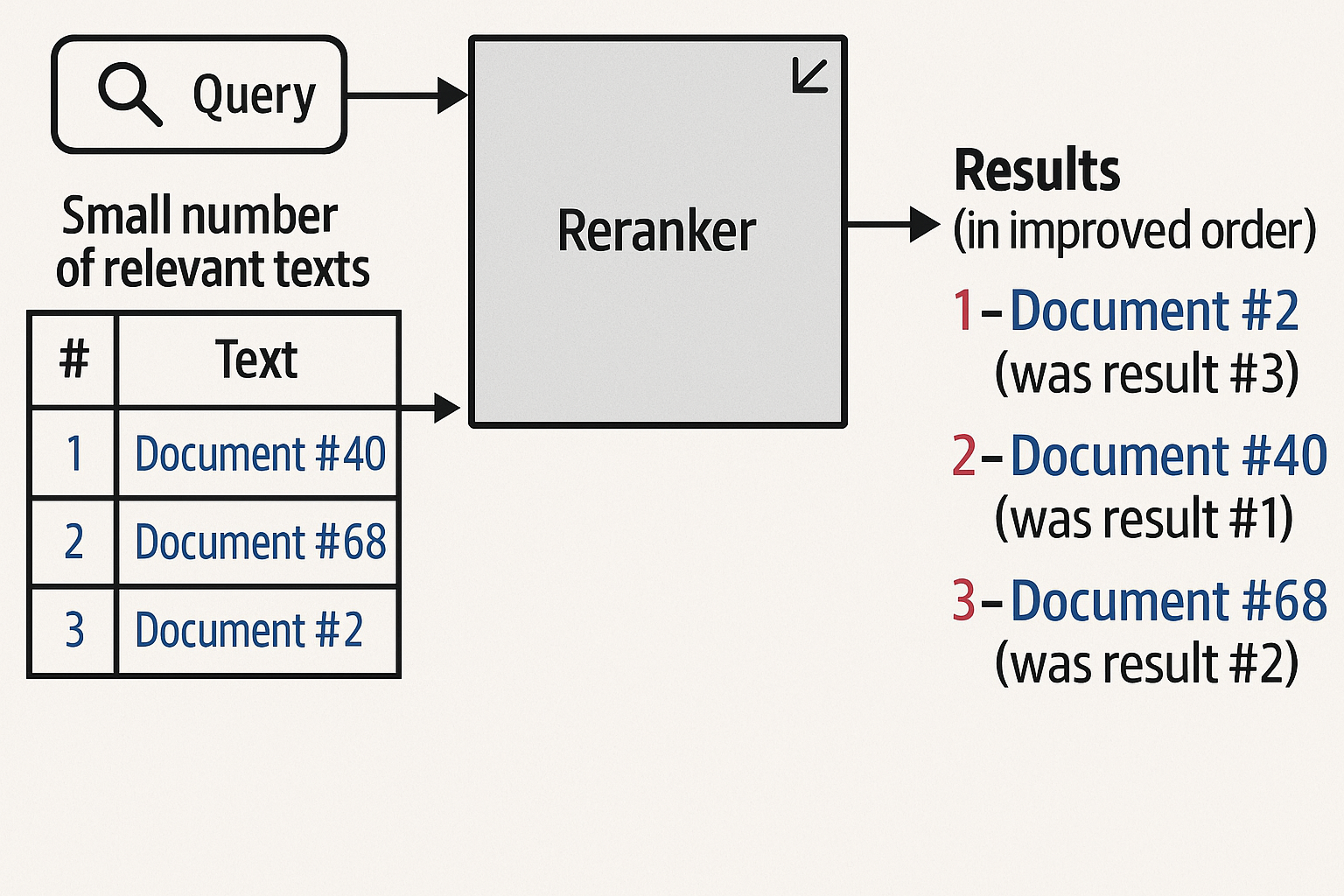
Reranking
An easier way to incorporate language models in an existing search pipeline is to use it as the final step to change the order of the search results based on relevance to the search query.
How reranking models work?
A popular way is to present the query and each result to an LLM working as a cross-encoder, then output the relevance score of each result, which will be used to determine the new ranking order. See more details in the paper “Multi-stage document ranking with BERT”.
Retrieval evaluation metrics
Two commonly used metrics include mean average precision (MAP) and normalized discounted cumulative gain (nDCG). Next we discussed MAP in more details.
Three major components for evaluating search systems:
- text archive
- a set of queries
- relevance judgements indicating which text archive are relevant for each query
Calculation steps with a concrete example:
Step 1. Key Concepts
- Precision — fraction of retrieved items that are relevant:
- Recall — fraction of relevant items that are retrieved:
Average Precision (AP) — average of precision values at each rank where a relevant item is retrieved.
Mean Average Precision (MAP) — mean of AP values across multiple queries.
Step 2. Simple Example (Single Query)
Suppose the system returns 5 documents ranked by confidence:
| Rank | Document | Relevant? |
|---|---|---|
| 1 | A | ✅ |
| 2 | B | ❌ |
| 3 | C | ✅ |
| 4 | D | ✅ |
| 5 | E | ❌ |
There are 3 relevant documents total (A, C, D).
Compute Precision at Each Relevant Rank
| Rank | Relevant? | Precision @ Rank |
|---|---|---|
| 1 | ✅ | 1/1 = 1.00 |
| 2 | ❌ | — |
| 3 | ✅ | 2/3 ≈ 0.667 |
| 4 | ✅ | 3/4 = 0.75 |
| 5 | ❌ | — |
Average Precision (AP)
Average of the precisions at relevant ranks:
Step 3. Extend to Multiple Queries → MAP
If we have two queries with APs:
| Query | AP |
|---|---|
| Q1 | 0.806 |
| Q2 | 0.900 |
Then:
Step 4. Summary Formula
For a single query q:
where P(k) is precision at cutoff k and rel(k)=1 if the item at rank k is relevant (else 0).
Then across Q queries:
Final Intuition
- AP answers: “For one query, how well did I rank relevant items?”
- MAP answers: “On average, how good is my ranking quality across all queries?”
Retrieval-Augmented Generation (RAG)
RAG incorporate search capabilities in addition to generation capabilities, and it can reduce the hallucinations and enable more use cases such as “chat with my data”.
Advanced RAG Techniques
Several techniques to improve the performance of RAG system:
Query rewriting: use an LLM to rewrite the query into one that aids the retrieval step in getting the right info (e.g., the search step may struggle if the original query is too verbose or need to refer previous info)
Multi-query RAG: search multiple queries if more than one is needed to answer a specific question. For example, with a query “compare Nvidia 2020 and 2023 financial results”, we may better make two search queries one for the results of 2020, and the other for 2023.
Multi-hop RAG: a series of sequential queries to ask more advanced questions such as “Who are the largest manufactures in 2023? Do they each make EVs?” (First search for largest manufacturer, then search if each one makes EV)
Query routing: give the model ability to search multiple data sources based on different intents (e.g., search HR questions in HR info system, and search customer data from CRM systems).
Agentic RAG: with more and more complex problems, LLM acts more as an agent to gauge the required info and utilize multiple data sources (as tools).
RAG Evaluation
Human evaluation or LLM-as-judge can be performed to evaluate the the generative search systems from the following axes:
- Fluency: if the generated text is fluent and cohesive
- Perceived utility: if the generated answer is helpful and informative
- Citation recall: the proportion of generated statements about the external world that are fully supported by their citations (
\frac{TP}{TP + FN}) - Citation precision: the propotion of the generated citations that support their associated statements (
\frac{TP}{TP + FP}) - Faithfullness: if the answer is consistent with the provided context
- Answer relevance: how relevant the answer is to the question