5 - Text Clustering and Topic Modeling
Text clustering allows for creative solutions and diverse applications such as
- outliers detection
- speedup labeling
- finding incorrectly labeled data
- topic modeling (discover topics in a large collection of textual data)
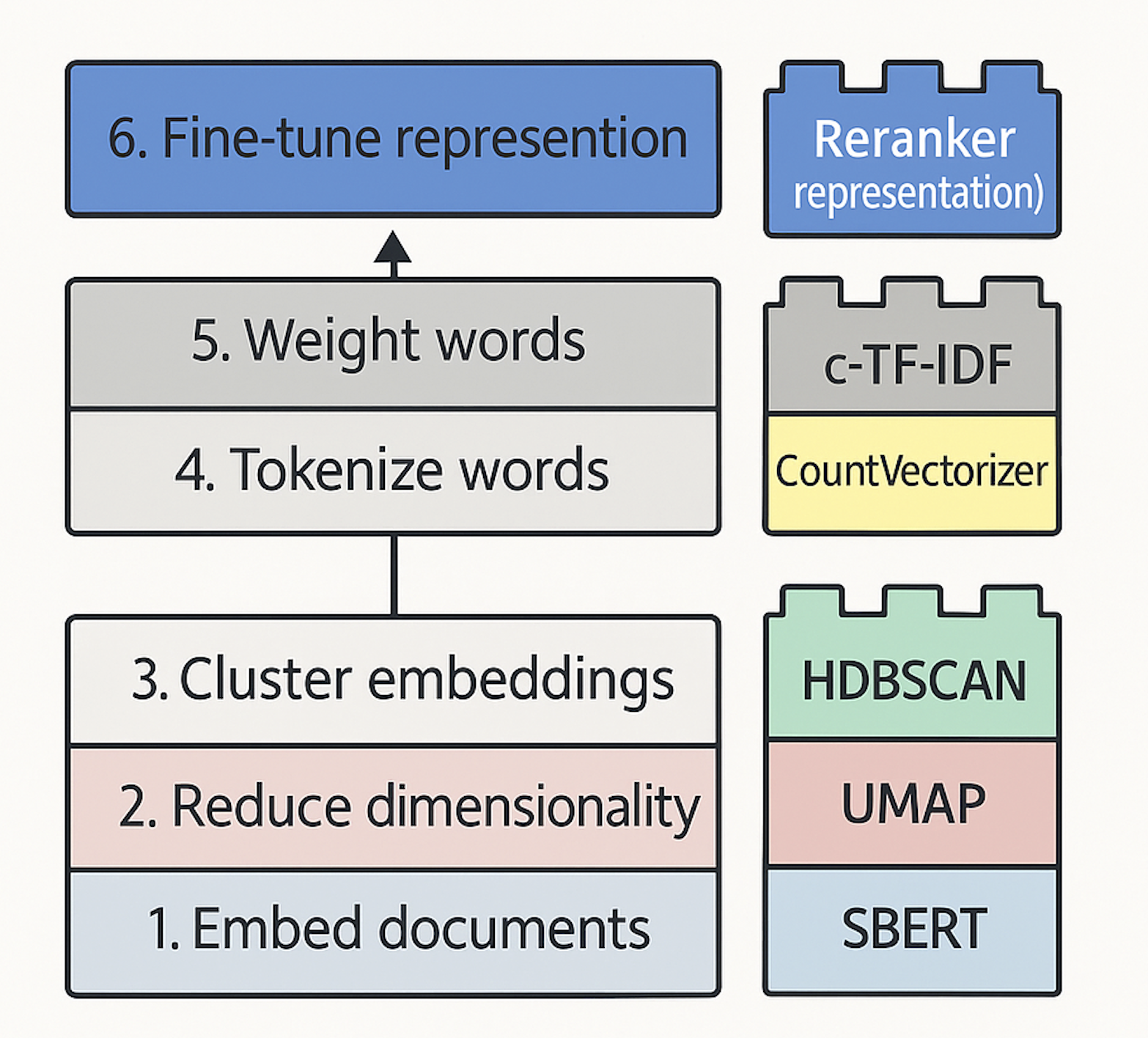
A Common Pipeline for Text Clustering
A general pipeline for text clustering:
- Convert the input documents to embeddings with embedding model
- Reduce the dimensionality of embeddings with dimension reduction model
- Find groups of semantically similar documents with clustering model
From Text Clustering to Topic Modeling
Pipeline
Topic modeling tries to find themes or latent topics in a collection of textual data.
| Approach | Description | Pros | Cons |
|---|---|---|---|
| Classical approach (e.g., LDA) | Assumes each topic is characterized by a probability distribution of words, and uses bag-of-words method to extract key words. | Easy to implement | No consideration on the meaning of the words and phrases |
| BERTopic (a modular topic modeling framework) | - Create clusters of semantically similar documents - Generate a distribution over words (e.g., bag-of-words, c[class]-TF-IDF) | - Modular pipeline - Can be adapted to different use cases using the same base model | - Still represents a topic through bag-of-words without considering the semantic structure |
Table: Comparison of the classical and BERTopic approaches for topic modeling.
Re-ranker Block
Re-rank the initial set of the words to improve the resulting representation (neural search) via representation models. We can further reduce the redundancy by applying maximal marginal relavance (MMR) to diversify our topic representations (e.g., remove redundant key words summaries and summary).
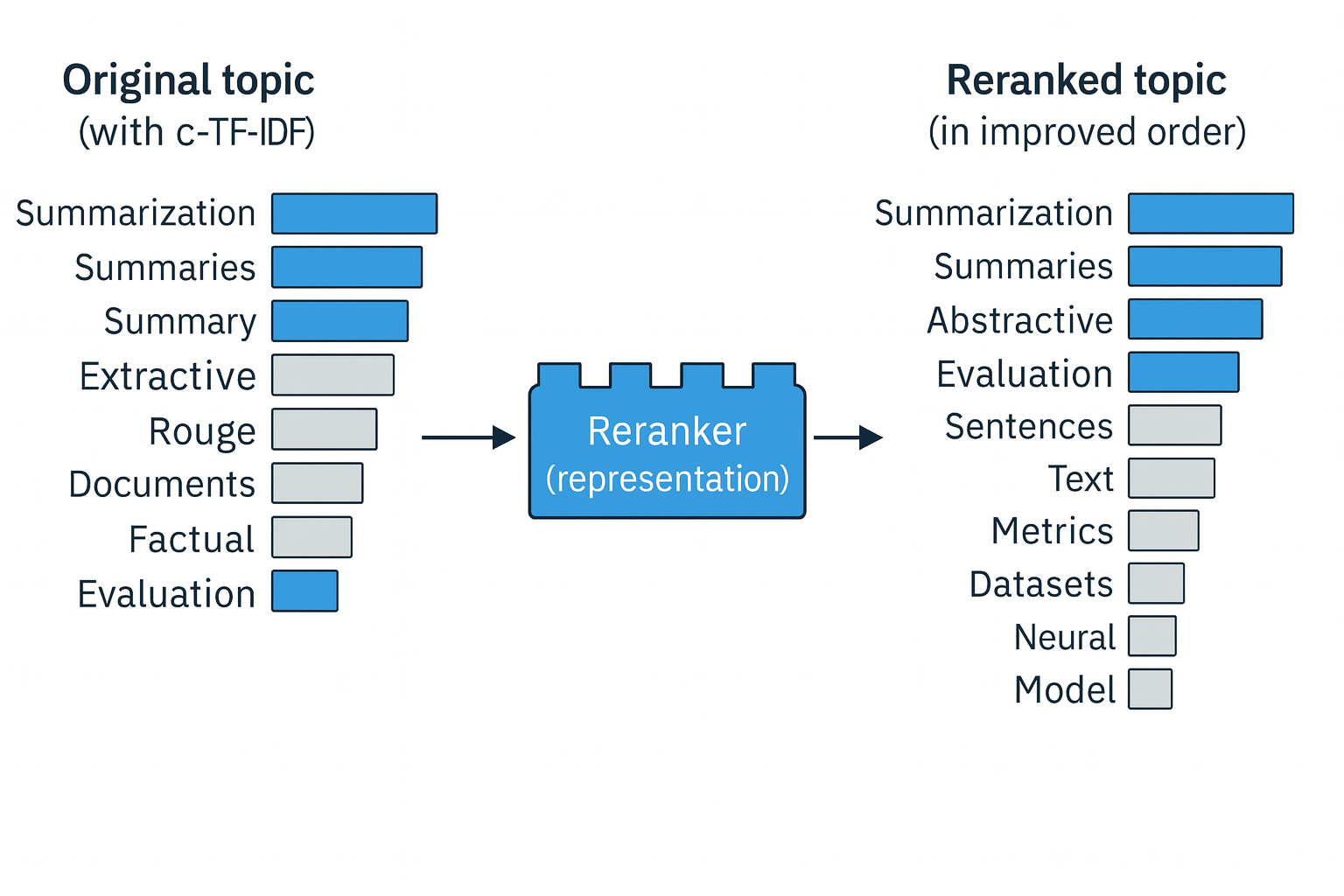
Here is the process of clustering, label topics, and reranker:
The Text Generation Block
We can further improve the interpretability of topics by generating highly interpretable labels with generative models based on some representative documents and the topic keywords.