2 - Tokens and Embeddings
Tokens and embeddings are two central concepts of using LLMs.
LLM Tokenization
How Tokenizers Prepare the Inputs to the Language Model
Highlevel overview:
Input prompt –> break it into pieces with tokenizer (token IDs) –> pass IDs/embeddings to LLM
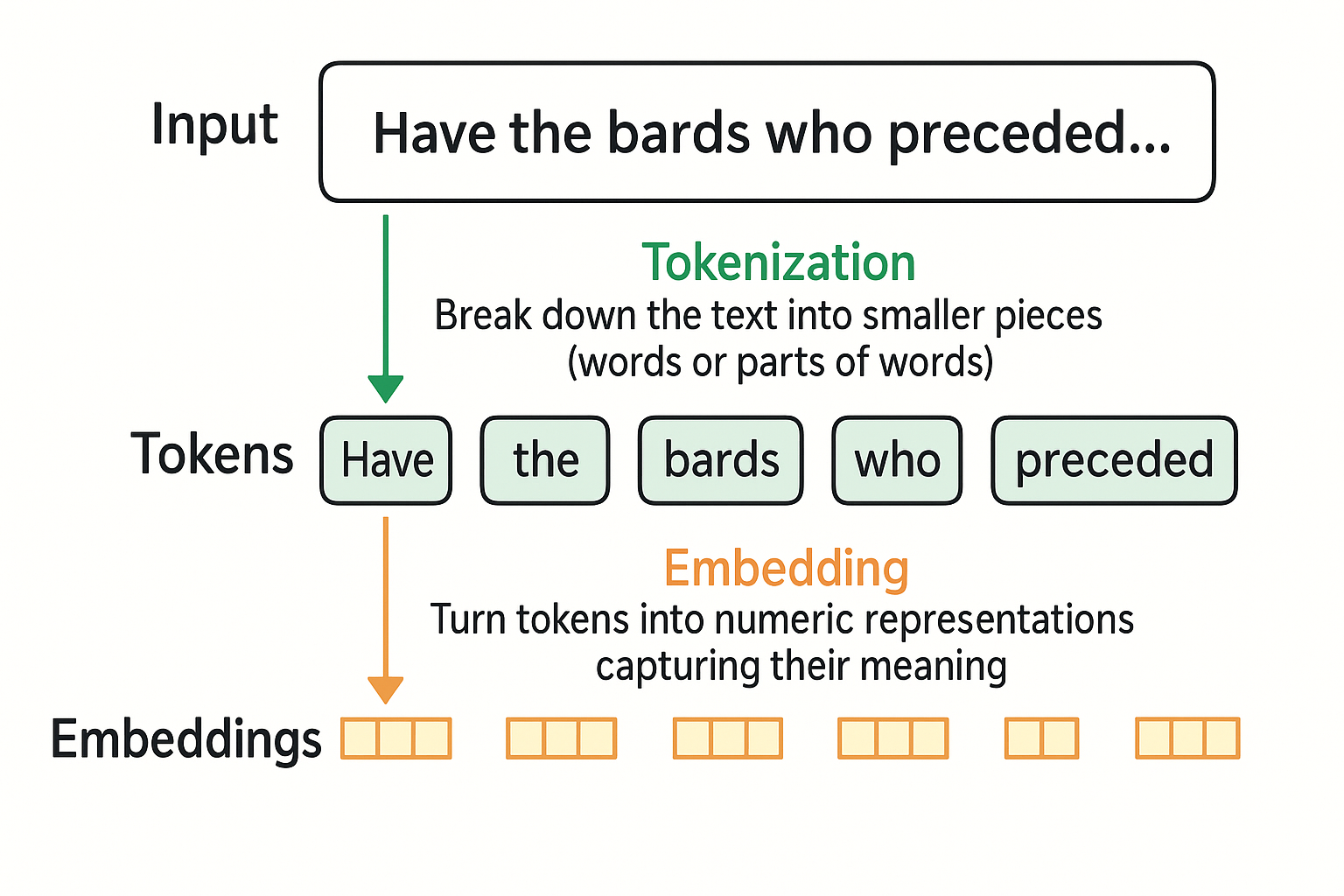
How Does the Tokenizer Break Down Text?
| No. | Phase | Description |
|---|---|---|
| 1 | Model design time | Choose a tokenization method (e.g., byte pair encoding used by GPT models, WordPiece by BERT) |
| 2 | Tokenization design | Choose the vocabulary size, what special tokens to use |
| 3 | Training time | Tokenizer needs to be trained on a specific dataset to establish the best vocabulary of subwords or characters that can accurately and efficiently represent any input text, minimizing the number of “unknown” tokens that appear (extra reference). |
When is the tokenizer used?
- process the input text
- decode the token IDs from the output of LLM to words/tokens
Word Versus Subword Versus Character Versus Byte Tokens
| Category | Description | Pros | Cons |
|---|---|---|---|
| word tokens | treat each word as a token | - suitable for recsys use cases | - unable to deal with new words after the tokenizer is trained (e.g., apology, apologize) |
| subword tokens | tokens can be full or partial words | - more expressive vocabulary (e.g., split apology to apolog and suffix tokens -y, -ize, -etic etc.) - able to represent new words by breaking down to smaller characters - fit more text within limited context length | |
| character tokens | split the tokens to characters | - able to represent new words | - makes modeling difficult - fit less context length |
| byte tokens | breaks down tokens into individual bytes for unicode chars | - can be competitive in multi-lingual scenarios |
Token Embeddings
The tokenization convert the language to a sequence of tokens, and the next step is to find the best numerical representation for these tokens, so the model can use them to calculate and model the patterns in the text.
A Language Model Holds Embeddings for the Vocabulary of Its Tokenizer
A pre-trained language model is linked with its tokenizer and cannot use a different tokenizer without training. When downloading a pretrained language model, a portion of the model is the embeddings matrix holding the embedding vectors for each token in the tokenizer vocabulary.
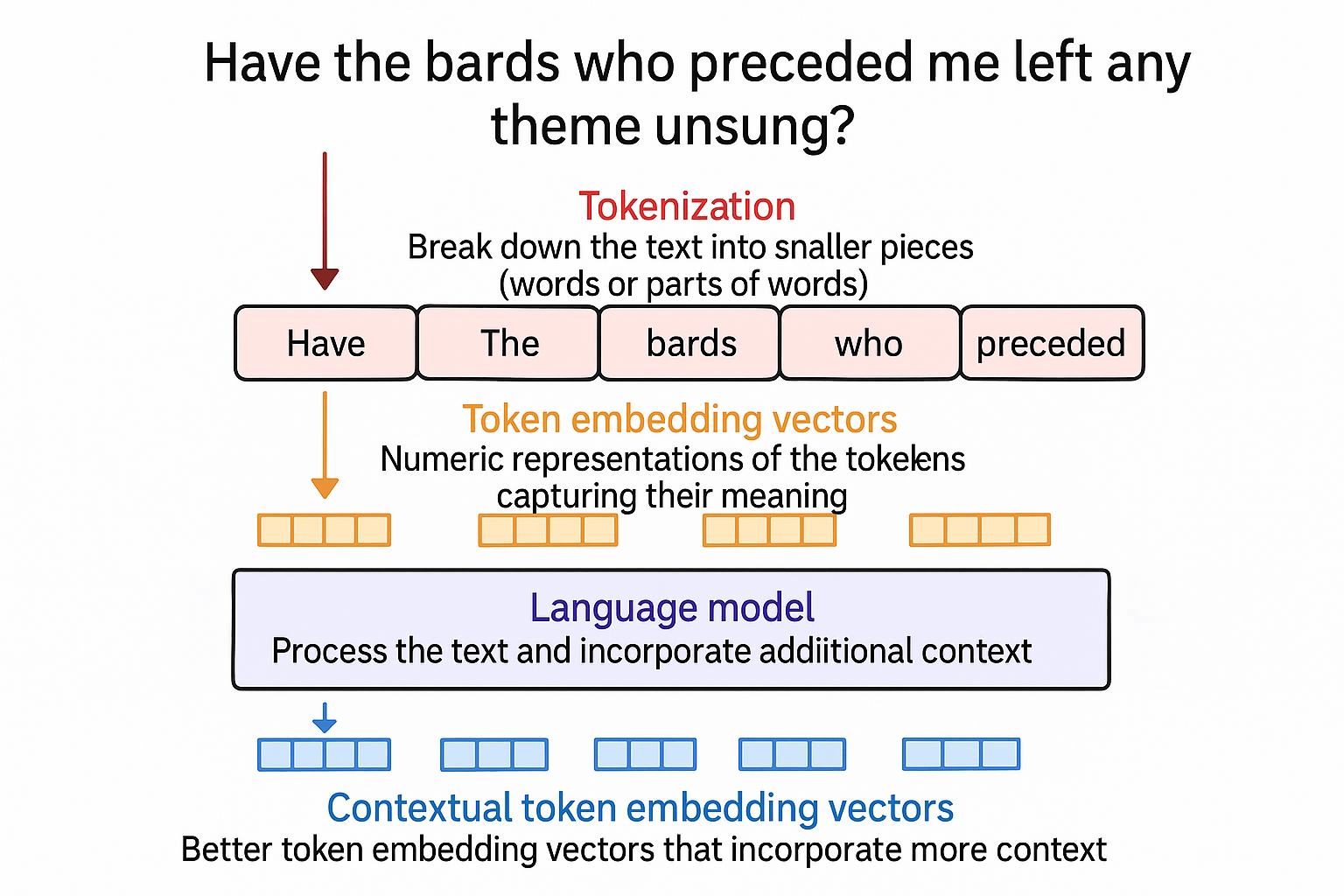
Creating Contextualized Word Embeddings with Language Models
To create better token embeddings than the above static ones, language models create contextualized word embeddings to represent a word with a different token based on its context.
Text Embeddings (for Sentences and Whole Documents)
A SINGLE vector embeding that represents a a longer text piece (e.g., sentence, documents), and the most common way to produce text embedding vector is average the values of all token embeddings.
Word Embeddings Beyond LLMs
Embeddings can also be useful in domains other than LLM such as recommender engines and robotics.
Next let’s learn about how the embeddings are generated from the Word2Vec algorithm.
How?
Train a neural network to predict if words commonly apear in the same context or not (i.e., a classification task).
Input:
- The embeddings of the words
Output:
- The updated embeddings of the words, so next time the model is presented with the vectors, they have a better chance of being correct based on the true labels (if they are true neighbors)
Training process:
Inputs embeddings –> prediction on labels/target value –> update the embeddings
Key considerations:
skip-gram: select neighboring words (e.g., use a sliding window to generate training examples: a central word as one input, and its two neighbor words as second inputs, the model will be trained to classify the neighbors as 1 if it is indeed neighbor otherwise 0)negative sampling: enrich the training dataset with examples of words that are NOT typically neighbors- Other tokenization: how to deal with capitalization, punctuation, and how many tokens in vocabulary
Embeddings for Recommendation Systems
RecSys is an example domain that the embeddings can be useful. An example process to make it useful here:
- Data loading: Playlists from radio stations.
- Word2Vec training (treat easch playlist as a sentence, each song in the playlist as a workd/token)
- Use the trained embeddings to find similar songs